




分析のためのデータ設計の重要性
入れるデータによってアウトプットが変わる
garbage in garbage out
(ゴミを入れればゴミが出る≒不要なデータからは不要な結果しか得られない)
これは、コンピューターの世界ではよく言われることです。
しかし、最初から適確で優良なデータだけを分析しても新たな発見はできないのではないかという考えもあります。
そうはいっても、どんな観点から分析してみてもゴミにしかならないデータが存在します。
特に、組織や事業の戦略立案に際しては、目的に沿ったデータ収集が必要になります。

データの代表性
組織や事業のマーケティング戦略を立案のために分析データを設計する際は、まず、分析対象の母集団を想定します。
例えば、自社ECサイトから離反を防止するための戦略立案を目的とすると、分析対象の母集団は何になるでしょう。
一番大きいサイズは、「現在または過去の利用者すべて」です。「現在」とは「過去」とは、それぞれ定義が必要ですが、自社のECサイトを何らか一度でも利用してくれてことのあるすべての顧客が、一番大きいサイズの母集団です。
そこから絞る際は、既に社内で分析がなされている離反の定義に沿って、その定義した範囲を母集団とします。
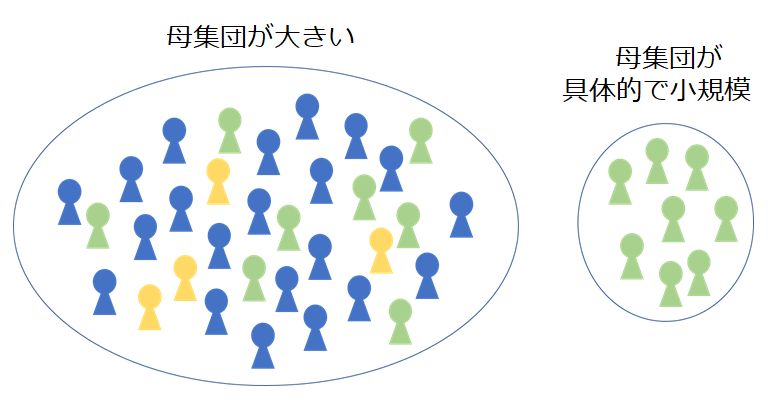
データのサンプリング
もし、想定した母集団が詳細で小規模ならば、可能な限りすべての顧客データを準備しましょう。
例えば、前回購入から2ヶ月以内に購入履歴がなかった人を「離反予備軍」と定義していて、顧客リストが1万件以内のような母集団を想定した場合、それらの母集団に含まれる戦略に必要な顧客情報を集めることは、それほど大変ではありません。(全数調査といいます。)
しかし、母集団が大きくすべてを集めることが難しいと、一部をサンプリング(標本抽出)することになります。(標本調査といいます。)
標本調査では、母集団の特性をできるだけ再現できるようにサンプリングを行い、その標本を分析することで、本来の調査目的である母集団の特性を推定します。
マーケティングリサーチでは、後者の標本調査が一般的で多用されています。
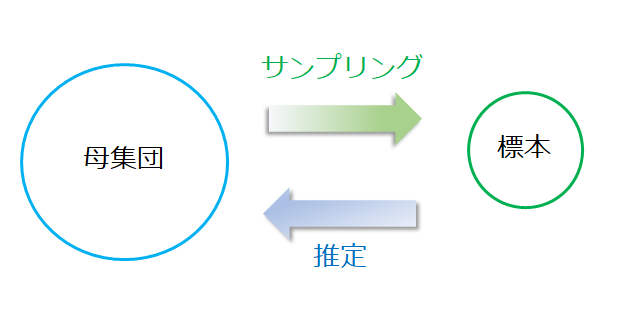
標本調査のためのサンプリングの方法は、大きく2種類(無作為抽出と有意抽出)あり、さらにそれぞれ具体的な方法が考案されています。
2種類の違いは、有意抽出は意図的に(非確率的に)、無作為抽出は無作為に(確率的に)抽出する方法です。
無作為抽出法の例
無作為抽出法の中で、最もシンプルな方法は、単純無作為抽出法で、母集団から乱数表を用いて必要数をサンプリングする方法です。
より発展的な抽出方法として、層化無作為抽出法や比例配分法があります。
前述のECサイトを例にすると、母集団が現在および過去に利用したすべての顧客とした場合、現在と過去の定義づけをし、「現在顧客」と「過去顧客」の2層に分け、それぞれから無作為抽出で標本をつくるといった方法です。あるいは、調査分析の目的にとって有効な別の層を設定し、層別に無作為抽出を行います。また、層別の大きさに比例した数をサンプリングする方法を比例配分法と呼びます。
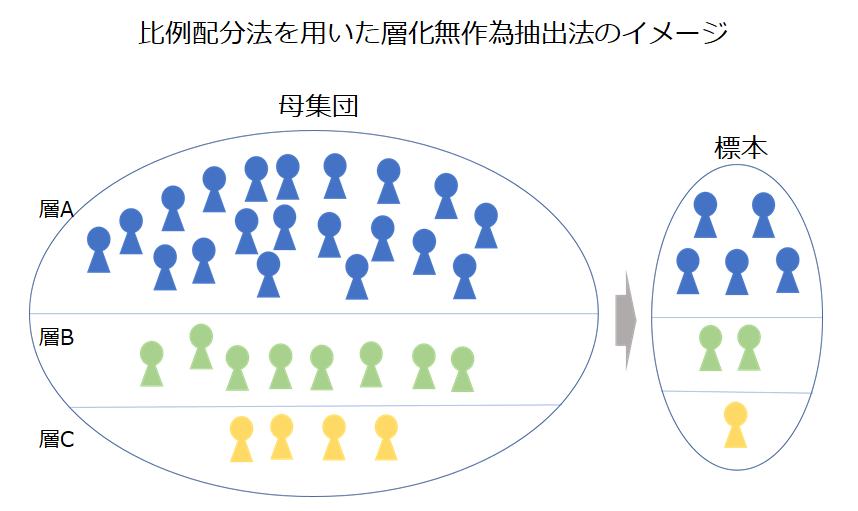
標本抽出においても層化することで調査の精度が高まる効果があり、可能な限り層化をしたほうがよいです。
データ設計に課題をお持ちの方は、5つのメニューよりお選びいただけます。
マーケティングの基本理論を使いこなすJMLAベーシックパスポート
顧客の潜在ニーズを引き出し商品開発を行う商品企画
人をワクワクさせる感動商品を想像する商品開発プロジェクト
顧客ニーズ(定量データ)からセグメンテーション→ターゲティングアナリスト
人の感性を定量的に分析し戦略立案を行う感性マーケティング
堀内香枝
最新記事 by 堀内香枝 (全て見る)
- 売れる商品は「利用シーン」を増やしている―市場を拡大する商品企画・マーケティングの発想法 - 2026年7月21日
- 母の日・父の日のプレゼント選びに見る顧客理解力 - 2026年5月22日
- 3事例に学ぶ 価値転換・価値の再定義ー共感と意味で選ばれる商品づくりとマーケティング - 2026年3月23日







